Partage d’un modèle d’intelligence artificielle : attention au risque de réidentification des données utilisées pour l’entraînement du modèle
Pour automatiser la pseudonymisation de ses décisions, la Cour de cassation est progressivement passée d’un moteur de règles[1] à un système d’intelligence artificielle reposant sur l’apprentissage automatique. Cette nouvelle approche est définie par la CNIL comme : « un champ d’études de l’intelligence artificielle qui vise à donner aux machines la capacité d’apprendre à partir de données, via des modèles mathématiques », soit un « procédé par lequel les informations pertinentes sont tirées d’un ensemble de données d’entraînement »[2].
Ainsi, ce changement de paradigme permet à la Cour de cassation de réaliser des gains de temps, et d’adapter son outil de pseudonymisation à une plus grande variété de contextes. Néanmoins, le recours aux modèles d’apprentissage automatique génère de nouveaux risques : notamment la potentielle réidentification des données personnelles ayant été utilisées pour l’entraînement de ce dernier.
Ainsi, le 31 janvier 2023, un justiciable a demandé à l’administration la communication du code source du logiciel, ainsi que le modèle d’intelligence artificielle en tant que tel, utilisé par la Cour de cassation afin de pseudonymiser ses décisions de justice avant leur publication. Si le code source du logiciel fait lui déjà l’objet d’une diffusion publique, le Président de la Cour a toutefois expressément refusé la communication du modèle d’intelligence artificielle entraîné.
Ainsi, l’avis rendu par la Commission d’accès aux documents administratifs (CADA) en date du 30 mars 2023[3] dernier consacre la possibilité d’obtenir la communication des modèles d’intelligence entraînés utilisés par l’administration (I.), sous réserve que cette communication ne permette pas à des tiers de procéder à la réidentification des données personnelles présentes dans les données d’entraînement du modèle (II.). Ainsi, il est nécessaire de garantir la confidentialité des données d’entraînement d’un modèle d’intelligence artificielle mis en production (III.).
1. Les modèles d’intelligence artificielle entraînés : des documents administratifs susceptibles d’être communiqués
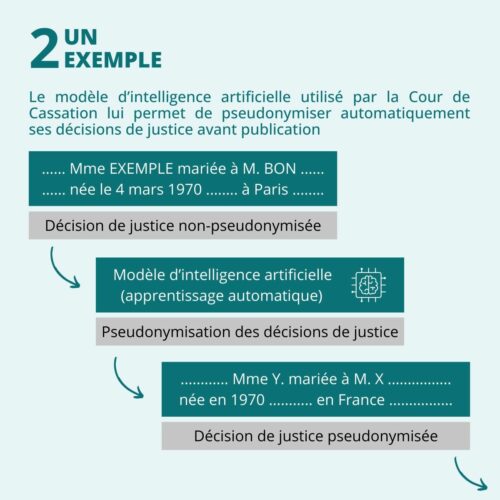
Le modèle d’intelligence artificielle utilisé par la Cour de cassation est composé de deux modèles d’intelligence artificielle ayant chacun subi une phase d’apprentissage propre[4] :
- Tout d’abord, un apprentissage non supervisé[5] d’un modèle de langage, qui permet d’obtenir des vecteurs multidimensionnels de mots, a été réalisé sur plus de 2 millions de décisions de justice ;
- Puis, un apprentissage supervisé[6] d’un algorithme de reconnaissance d’entités nommées, qui est une sous-tâche du premier, a été réalisé sur plusieurs milliers de décisions annotés.
Dès lors, la Commission d’Accès aux Documents Administratifs[7] (ou « CADA ») considère que de tels modèles, même entraînés, revêtent le caractère de documents administratifs, et peuvent le cas échéant faire l’objet d’une communication[3].
Pour rappel, l’article L300-2[8] du code des relations entre le public et l’administration définit les documents administratifs comme « les documents produits ou reçus, dans le cadre de leur mission de service public, par l’État, les collectivités territoriales ainsi que par les autres personnes de droit public ou les personnes de droit privé chargées d’une telle mission » ; et ce, « quels que soient leur date, leur lieu de conservation, leur forme et leur support ».
2. Le risque de réidentification des données : l’extraction des données personnelles d’entraînement à partir d’un modèle d’intelligence artificielle
Le principe de libre communication des documents administratifs connaît certaines exceptions, notamment lorsque ces derniers sont susceptibles de porter atteinte à la protection de la vie privée d’une personne comme prévu par l’article L311-6 du code des relations entre le public et l’administration [9]. Le cas échéant, seule la personne concernée peut obtenir la communication des informations présentes dans ledit document.
En effet, il est possible dans certains cas de figure de reconstituer les données utilisées pour entraîner un modèle d’intelligence artificielle : le risque de réidentification des données personnelles utilisées pour entraîner le modèle. Ainsi, ce risque résulte :
- De la structure de certains modèles d’intelligence artificielle qui conservent au sein de leurs paramètres les données d’entraînement dans leur forme initiale[10] ;
- Mais également de certaines formes d’attaques, dont les attaques « par inversion du modèle »[11] qui visent spécifiquement à reconstruire le jeu de données ayant permis d’entraîner un modèle.
Or en l’espèce, le président de la Cour de cassation considère que les données pseudonymisées dans les décisions rendues publiques peuvent être reconstitués via des opérations de rétro-ingénierie, sur la base des paramètres de configuration des modèles entraînés. En outre, l’algorithme de reconnaissance des entités nommées est un modèle génératif[12] ayant la capacité de mémoriser les données d’entraînement. Par conséquent, la CADA en déduit que « en l’état actuel des connaissances scientifiques » le risque de réidentification des personnes figurant dans les décisions présente « un caractère suffisant de vraisemblance pour être tenu pour acquis ».
En effet, un attaquant disposant du modèle et de l’ensemble de ses paramètres (soit une attaque menée en mode « boîte blanche »[13]) aurait davantage de facilités à reconstituer les données occultées présentes dans les décisions pseudonymisées, dès lors que ces dernières font partie du jeu de données d’entraînement du modèle. Ainsi, un modèle d’intelligence artificielle sera d’autant plus performant lorsqu’il est confronté à ses propres données d’entraînement.
Ainsi, la CADA considère que la communication desdits modèles d’intelligence artificielle est de nature à porter atteinte à la protection de la vie privée d’autrui, en permettant à des tiers de reconstituer le jeu de données utilisé aux fins d’apprentissage du modèle. Par conséquent, ces derniers peuvent réidentifier les personnes concernées dans les décisions de la Cour de cassation pseudonymisées.
3. Les mesures afin de limiter les risques de réidentification des données d’entraînement
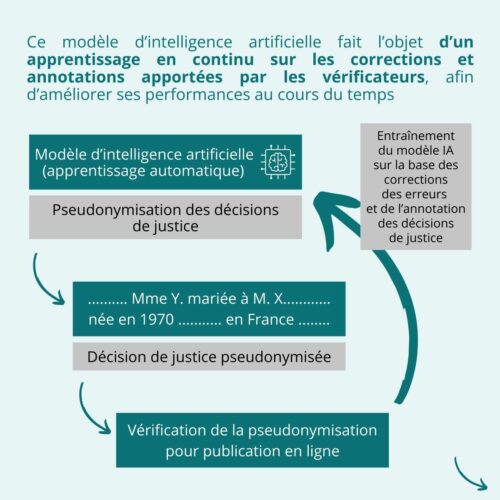
Lors du recours à un modèle d’apprentissage automatique, il est important de garantir la confidentialité des données ayant été utilisées afin d’entraîner le modèle, et de s’assurer que ces dernières ne soient pas rendues accessibles à des tiers (attaquants ou partenaires).
Le risque de réidentification des données d’entraînement doit donc être analysé en amont de la mise en production du modèle. En outre, il faut prendre en considération la structure du modèle ainsi que les différents scénarios d’attaque possibles. Cette analyse doit faire l’objet d’une documentation par le Responsable du traitement.
D’autre part, afin de limiter le risque, et selon le contexte, plusieurs mesures peuvent être envisagées, dont notamment :
- Privilégier le recours à des types d’algorithmes ne conservant pas les données d’entraînement dans la structure du modèle.
- Utiliser des données synthétiques[14] afin d’entraîner le modèle d’intelligence artificielle, dès lors que les données utilisées pour l’entraînement ne sont pas des données personnelles le risque de réidentification d’un individu est minimisé.
- Recourir à des API[15] plutôt qu’au partage du modèle en tant que tel[16], et limiter la fréquence et la portée des requêtes afin d’empêcher les attaquants d’accéder aux données d’entraînement.
- Brider la performance d’un modèle, ou en interdire les utilisations et applications, dans le cadre d’une tâche ou d’un contexte distinct.
- Restreindre l’accès à certaines informations aux attaquants, dont par exemple le score de confiance associé à une décision donnée, en le remplaçant par une simple mention sans précisions supplémentaires.
- Analyser l’ensemble des bibliothèques, et codes sources, utilisés afin de prévenir la présence de vulnérabilités, ou de failles de sécurité, permettant à des tiers de récupérer les données d’entraînement (notamment par le biais d’une porte dérobée).
-bibliographie
[1] Un logiciel permettant d’automatiser des décisions à l’aide d’une logique prédéfinie.
[2] CNIL, Glossaire de l’intelligence artificielle, consultable en ligne : https://www.cnil.fr/fr/definition/apprentissage-automatique#:~:text=L’apprentissage%20automatique%20(machine%20learning,donn%C3%A9es%2C%20via%20des%20mod%C3%A8les%20math%C3%A9matiques.
[3] CADA, Avis n°20230314 – Séance du 30/03/2023, consultable en ligne : https://www.cada.fr/20230314
[4] Cour de cassation, Moteur de pseudonymisation de la Cour de cassation, 14 Février 2023, https://github.com/Cour-de-cassation/moteurNER
[5] « L’apprentissage non supervisé est un procédé d’apprentissage automatique dans lequel l’algorithme utilise un jeu de données brutes et obtient un résultat en se fondant sur la détection de similarités entre certaines de ces données », CNIL, Glossaire de l’intelligence artificielle, consultable en ligne : https://www.cnil.fr/fr/definition/apprentissage-automatique#:~:text=L’apprentissage%20automatique%20(machine%20learning,donn%C3%A9es%2C%20via%20des%20mod%C3%A8les%20math%C3%A9matiques.
[6] « L’apprentissage supervisé est un procédé d’apprentissage automatique dans lequel l’algorithme s’entraîne à une tâche déterminée en utilisant un jeu de données assorties chacune d’une annotation indiquant le résultat attendu », CNIL, Glossaire de l’intelligence artificielle, consultable en ligne : https://www.cnil.fr/fr/definition/apprentissage-automatique#:~:text=L’apprentissage%20automatique%20(machine%20learning,donn%C3%A9es%2C%20via%20des%20mod%C3%A8les%20math%C3%A9matiques.
[7] La Commission d’accès aux documents administratifs est une autorité administrative indépendante créer par la loi no 78-753 du 17 juillet 1978 ayant pour mission de fournir des avis aux personnes dont les demandes de communications de documents détenus par l’administration ont fait l’objet d’un refus
[8] https://www.legifrance.gouv.fr/codes/article_lc/LEGIARTI000033218936
[9] Article L311-6 1° du code des relations entre le public et l’administration : « Ne sont communicables qu’à l’intéressé les documents administratifs : 1° Dont la communication porterait atteinte à la protection de la vie privée », legifrance.gouv.fr/codes/article_lc/LEGIARTI000037269056
[10] A titre d’exemple, la CNIL cite : « les algorithmes de clustering k-NN et de classification SVM », Laboratoire Numérique d’Innovation de la CNIL, Dossier Sécurité des systèmes d’IA, Avril 2022, p. 20, consultable en ligne https://linc.cnil.fr/sites/linc/files/atoms/files/linc_cnil_dossier-securite-systemes-ia.pdf
[11] Dit également « model inversion attacks », Les attaques par inversion visent à extraire une représentation moyenne de chacune des classes sur lesquelles le modèle a été entrainé », Laboratoire Numérique d’Innovation de la CNIL, Dossier Sécurité des systèmes d’IA, Avril 2022, p. 20, consultable en ligne https://linc.cnil.fr/sites/linc/files/atoms/files/linc_cnil_dossier-securite-systemes-ia.pdf
[12] « Par opposition à un modèle discriminatif, le modèle génératif permet à la fois de générer de nouveaux exemples à partir des données d’entraînement et d’évaluer la probabilité qu’un nouvel exemple provienne ou ait été généré à partir des données d’entraînement », CNIL, Glossaire de l’Intelligence Artificielle https://www.cnil.fr/fr/definition/modele-generatif
[13] Contrairement à une attaque en mode « boîte noire » l’attaquant connaît ici de nombreuses informations sur le système d’IA : « la distribution des données ayant servi à l’apprentissage du modèle (potentiellement l’accès à certaines parties de celles-ci), l’architecture du modèle, l’algorithme d’optimisation utilisé, ainsi que certains paramètres (par exemples les poids et les biais d’un réseau de neurones) », Laboratoire Numérique d’Innovation de la CNIL, Dossier Sécurité des systèmes d’IA, Avril 2022, p. 20, consultable en ligne : https://linc.cnil.fr/sites/linc/files/atoms/files/linc_cnil_dossier-securite-systemes-ia.pdf]
[14] La synthèse de données est une technique visant à générer des données par le biais d’un modèle d’intelligence artificielle dédié répliquant les caractéristiques et les propriétés statistiques de données réelles tout en introduisant une part d’aléatoire. Ces données sont alors dénommées « données synthétiques », elles peuvent alors être des données anonymes au sens du RGPD et être utilisés afin d’entraîner un modèle d’intelligence artificielle. Voir en ce sens : Information Commissionner’s Office, Guidance on Privacy-enhancing technologies (PETs), 19 juin 2023, https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/data-sharing/privacy-enhancing-technologies/what-pets-are-there/synthetic-data/
[15] « Une API (application programming interface ou « interface de programmation d’application ») est une interface logicielle qui permet de « connecter » un logiciel ou un service à un autre logiciel ou service afin d’échanger des données et des fonctionnalités », CNIL, Glossaire, https://www.cnil.fr/fr/definition/interface-de-programmation-dapplication-api
[16] Information Commissionner’s Office, Guidance on AI And Data Proteciton, septembre 2023, consultable en ligne : https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/artificial-intelligence/guidance-on-ai-and-data-protection/how-should-we-assess-security-and-data-minimisation-in-ai/#whatsecurityrisks